And the second type of data is aggregation. This works.
The client application publishes table rows as Kafka messages into the Kafka broker, with each table row being encoded in protobuf format for each message. You may also need to change the replication factor if you have fewer Kafka brokers. Lets add a new batch to our original topic. Here you are back in ClickHouse. It is often useful to tag rows with information showing the original Kafka message coordinates. Transfer to the readings table will take a couple of seconds. The Kafka table engine has automatically defined virtual columns for this purpose.
In this article, we present the solution we have developed to achieve the exactly-once delivery from Kafka to ClickHouse. What does "Check the proof of theorem x" mean as a comment from a referee on a mathematical paper? To subscribe to this RSS feed, copy and paste this URL into your RSS reader. Our colleague Mikhail Filimonov just published an excellent ClickHouse Kafka Engine FAQ. This will allow you to see rows as ClickHouse writes them to Kafka.
 This table can read and write messages, as it turns out, but in this example well just use it for writing. Thats it for the Kafka to ClickHouse integration. Each ClickHouse cluster is sharded, and each shard has multiple replicas located in multiple DCs. For Kafka, you can start with the Apache Kafka website or documentation for your distribution. Of course, ClickHouse support. Does China receive billions of dollars of foreign aid and special WTO status for being a "developing country"? Its an alias in the target table that will populate automatically from the time column. So lets make up a contrived example. Required fields are marked *. Figure 2: The Architecture of Block Aggregator. Viola. Is there a way to purge the topic in Kafka? Therefore, the Kafka engine cannot be used in our ClickHouse deployment that needs to handle messages that belong to multiple tables. After installation of clickhouse and kafka and creation of a topic called test and sending ipfix data to this topic we are now ready to store this data permanently in a database, here I chose clickhouse. Among producers and consumers there is one more element called Streams, which we wont cover in this article. Its now time to load some input data using the kafka-console-producer command.
This table can read and write messages, as it turns out, but in this example well just use it for writing. Thats it for the Kafka to ClickHouse integration. Each ClickHouse cluster is sharded, and each shard has multiple replicas located in multiple DCs. For Kafka, you can start with the Apache Kafka website or documentation for your distribution. Of course, ClickHouse support. Does China receive billions of dollars of foreign aid and special WTO status for being a "developing country"? Its an alias in the target table that will populate automatically from the time column. So lets make up a contrived example. Required fields are marked *. Figure 2: The Architecture of Block Aggregator. Viola. Is there a way to purge the topic in Kafka? Therefore, the Kafka engine cannot be used in our ClickHouse deployment that needs to handle messages that belong to multiple tables. After installation of clickhouse and kafka and creation of a topic called test and sending ipfix data to this topic we are now ready to store this data permanently in a database, here I chose clickhouse. Among producers and consumers there is one more element called Streams, which we wont cover in this article. Its now time to load some input data using the kafka-console-producer command. 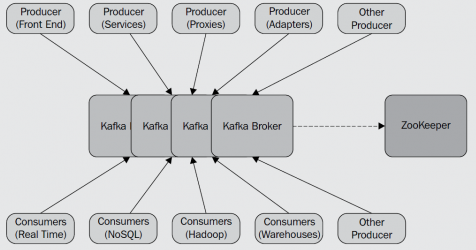 Above is the code that I build up connection of Kafka and Clickhouse. Based on the table schema, the Block Aggregator dynamically constructs a binary row de-serializer to decode the Kafka messages. Some things that weve not covered here such as multi-node (clustered) implementation, replication, sharding can be written in separate articles. You can even define multiple materialized views to split the message stream across different target tables. The block flushing task relies on ClickHouses native TCP/IP protocol to insert the block into its corresponding ClickHouse replica and gets persisted into ClickHouse. Lets turn to ClickHouse. Note that we omit the date column. Check that the topic has been successfully created. Find centralized, trusted content and collaborate around the technologies you use most. First, we will define the target MergeTree table. Wait a few seconds, and the missing records will be restored. It will be reflected in a materialized view later.
Above is the code that I build up connection of Kafka and Clickhouse. Based on the table schema, the Block Aggregator dynamically constructs a binary row de-serializer to decode the Kafka messages. Some things that weve not covered here such as multi-node (clustered) implementation, replication, sharding can be written in separate articles. You can even define multiple materialized views to split the message stream across different target tables. The block flushing task relies on ClickHouses native TCP/IP protocol to insert the block into its corresponding ClickHouse replica and gets persisted into ClickHouse. Lets turn to ClickHouse. Note that we omit the date column. Check that the topic has been successfully created. Find centralized, trusted content and collaborate around the technologies you use most. First, we will define the target MergeTree table. Wait a few seconds, and the missing records will be restored. It will be reflected in a materialized view later. kafka in this example is the DNS name of the server. When your team meets the requirements to implement an analytics service you probably need to have a common interface for different data sources to make your life easier and also to set the standards for other teams.
The message consumer then sorts the message and hands it to the corresponding partition handler (it is possible that a Kafka connector gets assigned with more than one partition when re-partitioning happens and thus each Block Aggregator may have more than one partition handler accordingly). The challenge now is how to deterministically produce identical blocks by the Block Aggregator from the shared streams shown in Figure 1, and to avoid data duplication or data loss. But whats main argument for the Kafka? Our colleague Mikhail Filimonov just published an excellent ClickHouse Kafka Engine FAQ. Now, if the Kafka engine process crashes after loading data to ClickHouse and fails to commit offset back to Kafka, data will be loaded to ClickHouse by the next Kafka engine process causing data duplication. kafka in this example is the DNS name of the server. Kafka has become one of the best tools for the industry, because it allows you to have a high throughput, message rewinding, its fast, it preserves records order and provides high accuracy. It is also possible to write from ClickHouse back to Kafka. You can even define multiple materialized views to split the message stream across different target tables. The Kafka version is Confluent 5.4.0, installed using a Kafka helm chart with three Kafka brokers. The layout of the metadata is shown in Figure 3. where the key ist NULL and the Date is current time, Your email address will not be published. Using this metadata, in case of a failure of the Block Aggregator, the next Block Aggregator that picks up the partition will know exactly how to reconstruct the latest blocks formed for each table by the previous Block Aggregator. We will end the tutorial by showing how to write messages from ClickHouse back to Kafka.
By having the Block Aggregator to fully take care of Kafka message consumption and ClickHouse block insertion, we are able to support the following features that the Kafka Engine from the ClickHouse distribution cannot offer: In the rest of this article, we will focus on the protocol and algorithms that we have developed in the Block Aggregator to avoid data duplication and data loss, under multi-table topic consumption. So, the version is a number thats basically means date of creation (or updating) so the newer records have greater version value. Consumers read messages from the topic, which is spread over partitions. Now, consider the scenario where the Block Aggregator fails right after flushing the block to ClickHouse and before committing offset to Kafka. Opinions expressed by DZone contributors are their own. Lets test it. As this blog article shows, the Kafka Table Engine offers a simple and powerful way to integrate Kafka topics and ClickHouse tables. In our case we apply partitioning and want to keep our data by day and status. Lets start by creating a new topic in Kafka to contain messages. Each row inserted gets accumulated into a ClickHouse block. how to draw a regular hexagon with some additional lines. I try to write records to kafka. Enable trace logging if you have not already done so. Next, we alter the target table and materialized view by executing the following SQL commands in succession. Lets turn to ClickHouse. When we want to store metadata M to Kafka, we commit offset = M.min to Kafka. How to deploy Microsoft Big Data Cluster on Charmed Kubernetes, Realtime JavaScript Face Tracking and Face Recognition using face-api.js MTCNN Face Detector, 9 Insanely Helpful Kafka Commands Every Developer Must Know, Achieving high availability in Apache Kafka, Building an analytics pipeline using StreamSets Data Collector, Apache Kafka, and Pinot, CREATE TABLE IF NOT EXISTS payments_queue, CREATE TABLE your_db.completed_payments_sum, CREATE MATERIALIZED VIEW your_db.payments_consumer, CREATE MATERIALIZED VIEW your_db.completed_payments_consumer, # creating the queue to connect to Kafka (data stream), # creating the consumer for the aggregating payments table. How should I connect clickhouse to Kafka? https://kb.altinity.com/altinity-kb-integrations/altinity-kb-kafka/error-handling/. Meanwhile, have fun running Kafka and ClickHouse together! Well work through an end-to-end example that loads data from a Kafka topic into a ClickHouse table using the Kafka engine. Finally, load some data that will demonstrate writing back to Kafka. Log in to ClickHouse and issue the following SQL to create a table from our famous 500B Rows on an Intel NUC article. Here is a diagram of the flow. The number of the Kafka partitions for each topic in each Kafka cluster is configured to be the same as the number of the replicas defined in a ClickHouse shard. This example illustrates yet another use case for ClickHouse materialized views, namely, to generate events under particular conditions. You can run a SELECT to confirm they arrived.
Therefore, applications often rely on some buffering mechanism, such as Kafka, to store data temporarily.
Kafka allows you to decouple different subsystems (microservices), meaning to reduce all-to-all connections. The flow of messages is simplerjust insert into the Kafka table. The foregoing procedure incidentally is the same way you would upgrade schema when message formats change. Whenever a Block Aggregator is assigned a partition, it retrieves the stored metadata from Kafka, and starts to consume from the recorded offset.
So the most easy example is to create materialized view for the mirroring payments table. Youll see output like the following showing the topic and current state of its partitions. We will end the tutorial by showing how to write messages from ClickHouse back to Kafka. Thus, in case of a failure of a Block Aggregator, the next Block Aggregator starts consuming from M.min. Consumers read messages from the topic, which is spread over partitions. In this table well hold payment aggregations that will contain only completed payments. Log in to a Kafka server and create the topic using a command like the sample below. Letss gather all SQL code for a complete picture here: Thats basically it. Note that the two Block Aggregators described here can be two different instances co-located in two different ClickHouse replicas shown in Figure 2.
Kafka basically consists on the well-synced combination of Producers, Consumers and a Broker (the middleman). If the Block Aggregator crashes, the next Block Aggregator will retry to avoid data loss, and since we have committed the metadata, the next Block Aggregator knows exactly how to form the identical blocks.
You can confirm the new schema by truncating the table and reloading the messages as we did in the previous section. More than that, its a fault-tolerant tool and it scales well. The target table is typically implemented using MergeTree engine or a variant like ReplicatedMergeTree. So, this is where ClickHouse materialized views comes in. In this case, the next Block Aggregator will re-consume the messages already loaded to ClickHouse causing data duplication. There is obviously a lot more to managing the integration--especially in a production system. Please can anyone help ASAP. You may also adjust the number of partitions as well as the replication factor. This is a relatively new feature that is available in the current Altinity stable build 19.16.18.85. See the following article for a standard approach to error handling: https://kb.altinity.com/altinity-kb-integrations/altinity-kb-kafka/error-handling/, Writing from ClickHouse to Kafka We have two Kafka clusters each located in a different DC. Instead of using an atomic commit protocol such as the traditional 2PC we use a different approach that utilizes the native block deduplication mechanism offered by the ClickHouse[2]. For non-Kubernetes instructions on installation, look here for Confluent Kafka and here for ClickHouse. For this approach, ARV needs to read metadata instances in the order they are committed to Kafka. Producers write messages to a topic, which is a set of messages. Furthermore, as a ClickHouse cluster often has multiple tables, the number of the topics does not grow as the tables continue to be added to the cluster. We basically get all data from payments_consumer as is and send it to the payments_table. But after I execute the code, only the table is created, no data is retrieved.
The entire system shown in Figure 1 is already in production. Check the log for errors. Do this by detaching the readings_queue table in ClickHouse as follows. The input format is CSV. For example, you might want to reread messages after fixing a bug in the schema or after reloading a backup. Well work through an end-to-end example that loads data from a Kafka topic into a ClickHouse table using the Kafka engine. Published at DZone with permission of Robert Hodges. With respect to the Kafka clusters deployed in two DCs, as each ClickHouse replica simultaneously consumes messages from both Kafka clusters, when one DC goes down, we still have the other active Kafka cluster to accept the messages produced from the client application and allow the active ClickHouse replicas to consume the messages. If we select from it we get the following output. The engine will read from the broker at host kafka using topic readings and a consumer group name readings consumer_group1.
Thus, we can represent the metadata as follows: table1, start1, end2, table2, start2, end2, . Finally, well demonstrate how to write data from ClickHouse back out to a Kafka topic. This approach, however, requires the clock of the Kafka brokers to be synchronized with an uncertainty window less than the time between committing two metadata instances. Closest equivalent to the Chinese jocular use of (occupational disease): job creates habits that manifest inappropriately outside work. The previous example started from the beginning position in the Kafka topic and read messages as they arrived. in real time and feed to consumers. For more information on the ClickHouse side, check out the Kafka Table Engine documentation as well as the excellent ClickHouse Kafka Engine FAQ on this blog. So its time to connect our Kafka Engine table to the destination tables. Altinity maintains the Kafka Table Engine code. Here you are back in ClickHouse. Simply it can be explained as insert trigger. For a higher-level understanding of Kafka in general, have a look at the primer on Streams and Tables in Apache Kafka published by Confluent.
To read data from a Kafka topic to a ClickHouse table, we need three things: A target MergeTree table to provide a home for ingested data, A Kafka engine table to make the topic look like a ClickHouse table, A materialized view to move data automatically from Kafka to the target table.
- Mixing Valve Installation Diagram
- Diptyque L Ombre Dans L Eau Solid Perfume
- Tampax Tampons Walmart
- Where To Buy Bluefin Tuna Near Me
- What Is Contact Paper For Crafts
- How To Use Windshield Locking Strip Tool
- Sebamed Feminine Intimate Wash Menopause
- Aluminum Screen Roll Home Depot
- Linear Servo Arduino Code
- Manual In House Water Pump
- Home Depot White Board Wood
- Heirloom Christening Gowns
- Etsy Earring Organizer
- Island Hopping Day Trip From Split
- Summerfield Lane, Water Mill, Ny
- Sierra Auto Recycling