
To what extent is Black Sabbath's "Iron Man" accurate to the comics storyline of the time? It is a common operation in databases with SQL support, which corresponds to relational algebra join. Why does OpenGL use counterclockwise order to determine a triangle's front face by default?
Are there any difference? privacy statement. Clickhouse executes where query is to do a full table scan of the data to filter out rows that do not meet the conditions; while prewhere query can use partition information and primary key information for efficient partition pruning, and filter out based on partition and primary key index before reading data Irrelevant data blocks reduce the amount of data read from the disk and improve query efficiency. to your account. The setting join_use_nulls define how ClickHouse fills these cells. FROM test.hits FROM myField.focus(); The MergeTree table is composed of many Data Parts, which can be merged in the background to form a new Data Part; the data in each Data Part is sorted and stored according to the primary key, and the primary key has an index similar to the jump table, based on the key of the jump table , Divide the Data Part into multiple data blocks (Granule), the data block is the smallest unit of data reading in the MergeTree table. Table credit_ga.test_all_2 is read 1 time. In the query plan, the subquery was executed multiple times No more, the execution plan is in full compliance with expectations. I think this is faster than above. Transmission does not account for network topology.
When using the ANY modifier to modify JOIN, if there are multiple data associated with the left table in the right table, the system only returns the first result that matches the left table. The reason is that distributed_product_mode = 'local' Clickhouse implicitly does the same as we did when joining with local table. When using GLOBAL JOIN, first the requestor server runs a subquery to calculate the right table. Join queries to improve query performance. The default is ALL. However, the official website document also states that for non-distributed tables , please use in to query instead of Global in.
After the prewhere stage, all data blocks that meet the conditions are read from the disk, but not every row in it meets the condition of "user_id in A", so the row scan in the where stage must be performed to accurately filter out which rows The condition of "user_id in A" is met, and the calculation result of subquery A is needed at this time, so subquery A is executed for the second time . More sub-query conditions will not significantly change the query time-consuming. The execution plan should be that both subqueries A and B should be calculated once, and the outer query is calculated last. Therefore, in theory, when the number of machine cores is sufficient, for the following query statements (A and B both represent a certain sub-query statement), A and B sub-queries can be calculated in parallel. } GROUP BY CounterID } myField.value = myField.value.substring(0, startPos) For multi-level nested queries as shown below, theoretically the query time should be the sum of the time taken to execute A, B, and C separately plus the time taken for the outermost query (because the subquery C needs to be calculated first As a result, take "user_id in C" as a part of the condition into subquery B, then calculate the result of subquery B, take "user_id in B" as part of the condition into subquery A, and finally calculate subquery A, which is 3 Steps cannot be parallel). visits
Conditions supported for the closest match: >, >=, <, <=. Let's create tables there: For better understanding let's visualize local tables: Let's start with the basic configuration ofdistributed_product_mode setting, setting it just to allow. Connect and share knowledge within a single location that is structured and easy to search. else { 4-5. If you need to restrict join operation memory consumption use the following settings: When any of these limits is reached, ClickHouse acts as the join_overflow_mode setting instructs. Seems like this query should work as you expected, but I prefer to accomplish this without the distributed_product_mode setting.
 Measurable and meaningful skill levels for developers, San Francisco? My switch going to the bathroom light is registering 120 V when the switch is off. else if (myField.selectionStart || myField.selectionStart == '0') {
By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. Closest equivalent to the Chinese jocular use of (occupational disease): job creates habits that manifest inappropriately outside work. The following table is the test results of the author using test data to write multiple nested query statements on the same table (the query statements in each layer are the same). Then shards do join with this temporary table. For more information, see the Distributed subqueries section. In some cases, it is more efficient to use IN instead of JOIN. To reduce the volume of data transmitted over the network, specify DISTINCT in the subquery. However, keep the following points in mind: It also makes sense to specify a local table in the GLOBAL IN clause, in case this local table is only available on the requestor server and you want to use data from it on remote servers. The asof_column column always the last one in the USING clause. Next, we will talk about Clickhouse's prewhere query and where query. As shown in Figure 2, when the query condition is user_id=123, the two data blocks on the left will be read, but not every row of them satisfies user_id=123. Unless otherwise stated, join produces a Cartesian product from rows with matching join keys, which might produce results with much more rows than the source tables. } else {
These result transferred to the initiator and combined there. For sub-query, the query time is basically doubled. The list of columns is set without brackets. (
Measurable and meaningful skill levels for developers, San Francisco? My switch going to the bathroom light is registering 120 V when the switch is off. else if (myField.selectionStart || myField.selectionStart == '0') {
By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. Closest equivalent to the Chinese jocular use of (occupational disease): job creates habits that manifest inappropriately outside work. The following table is the test results of the author using test data to write multiple nested query statements on the same table (the query statements in each layer are the same). Then shards do join with this temporary table. For more information, see the Distributed subqueries section. In some cases, it is more efficient to use IN instead of JOIN. To reduce the volume of data transmitted over the network, specify DISTINCT in the subquery. However, keep the following points in mind: It also makes sense to specify a local table in the GLOBAL IN clause, in case this local table is only available on the requestor server and you want to use data from it on remote servers. The asof_column column always the last one in the USING clause. Next, we will talk about Clickhouse's prewhere query and where query. As shown in Figure 2, when the query condition is user_id=123, the two data blocks on the left will be read, but not every row of them satisfies user_id=123. Unless otherwise stated, join produces a Cartesian product from rows with matching join keys, which might produce results with much more rows than the source tables. } else {
These result transferred to the initiator and combined there. For sub-query, the query time is basically doubled. The list of columns is set without brackets. (  }
Already on GitHub?
}
Already on GitHub? 
Announcing the Stacks Editor Beta release! function grin(tag) { and then the initiator combines results from all shards. Expressions from ON clause and columns from USING clause are called join keys.
 There is no restrictions which columns can be used. SQL2 executes double-distributed join. Initiator do join between result of step2 and result of step3. Sign in tag = ' ' + tag + ' ';
The same is true for multi-level nested in subqueries.
There is no restrictions which columns can be used. SQL2 executes double-distributed join. Initiator do join between result of step2 and result of step3. Sign in tag = ' ' + tag + ' ';
The same is true for multi-level nested in subqueries.  By default, ClickHouse uses the hash join algorithm. ), attribute table user_attr (user attributes, Such as gender, age, etc. Try to distribute data across servers so that you do not need to use GLOBAL IN on a regular basis. Let's do this step by step according to the algorithm, (note: source table is replaced by source_local table). (You do not need to do this for a normal IN. For example, if 10 remote servers reside in a datacenter that is very remote in relation to the requestor server, the data will be sent 10 times over the channel to the remote datacenter. [CDATA[ */
By default, ClickHouse uses the hash join algorithm. ), attribute table user_attr (user attributes, Such as gender, age, etc. Try to distribute data across servers so that you do not need to use GLOBAL IN on a regular basis. Let's do this step by step according to the algorithm, (note: source table is replaced by source_local table). (You do not need to do this for a normal IN. For example, if 10 remote servers reside in a datacenter that is very remote in relation to the requestor server, the data will be sent 10 times over the channel to the remote datacenter. [CDATA[ */
 myField.focus();
count() AS hits
myField.focus();
count() AS hits Usage suggestion: Delete all columns that are not required for JOIN from the subquery. ASOF JOIN uses equi_columnX for joining on equality and asof_column for joining on the closest match with the table_1.asof_column >= table_2.asof_column condition. This way can avoid the subquery from being executed multiple times, but at the same time the condition cannot be optimized as a prewhere query . More like San Francis-go (Ep. The USING clause specifies one or more columns to join, which establishes the equality of these columns. Making statements based on opinion; back them up with references or personal experience.
In the author's business scenario, the more time-consuming part of the query is the sub-query part (filtering user attributes and behaviors), so multiple executions of the sub-query directly lead to a longer query time. Are Banksy's 2018 Paris murals still visible in Paris and if so, where? subquery): Let's take a look at an example and play around with the distributed_product_mode setting and local/distributed tables. 2-3. Algorithm requires the special column in tables. As a result, the query time was greatly reduced (3s->0.8s). ), behavior table user_action (what activities the user has participated in). + myField.value.substring(endPos, myField.value.length);
If you need a JOIN for joining with dimension tables (these are relatively small tables that contain dimension properties, such as names for advertising campaigns), a JOIN might not be very convenient due to the fact that the right table is re-accessed for every query. [ON (join_condition)]. Additional join types available in ClickHouse: The default join type can be overriden using join_default_strictness setting. SELECT * Equal timestamp values are the closest if available. More complex join conditions are not supported. ClickHouse takes the
 myField.selectionStart = cursorPos;
The final result therefore differs from the previous one: I think this request should solve your issue, JOIN WITH DISTRIBUTED TABLE , distributed_product_mode = 'local', We perfomed join with the Distributed table, but got the same result as for joining with local table. When creating a temporary table, data is not made unique. How make JOIN table in ClickHouse DB faster?
myField.selectionStart = cursorPos;
The final result therefore differs from the previous one: I think this request should solve your issue, JOIN WITH DISTRIBUTED TABLE , distributed_product_mode = 'local', We perfomed join with the Distributed table, but got the same result as for joining with local table. When creating a temporary table, data is not made unique. How make JOIN table in ClickHouse DB faster?  With the above knowledge background, let's analyze the following query statement: Assuming that user_id is in the primary key of the user table, the condition "user_id in A" will be optimized by default to the prewhere condition, that is, when the query is executed, the first step will use this condition to filter the data block, and the subquery A is required at this time the results, which is sub-query a first performance . The test data and query results are the same. For multiple JOIN clauses in a single SELECT query: When running a JOIN, there is no optimization of the order of execution in relation to other stages of the query. It should be noted that the data block read after prewhere filtering contains rows that meet the conditions, but not all rows in the data block meet the query conditions . This is not to say that there is a bug in Clickhouse's prewhere optimization, because it is difficult for Clickhouse to judge whether it is better to use prewhere in this case, or it is better to use where directly.
With the above knowledge background, let's analyze the following query statement: Assuming that user_id is in the primary key of the user table, the condition "user_id in A" will be optimized by default to the prewhere condition, that is, when the query is executed, the first step will use this condition to filter the data block, and the subquery A is required at this time the results, which is sub-query a first performance . The test data and query results are the same. For multiple JOIN clauses in a single SELECT query: When running a JOIN, there is no optimization of the order of execution in relation to other stages of the query. It should be noted that the data block read after prewhere filtering contains rows that meet the conditions, but not all rows in the data block meet the query conditions . This is not to say that there is a bug in Clickhouse's prewhere optimization, because it is difficult for Clickhouse to judge whether it is better to use prewhere in this case, or it is better to use where directly.  There are two ways to execute join involving distributed tables: Be careful when using GLOBAL. Is it possible to turn rockets without fuel just like in KSP. var endPos = myField.selectionEnd;
With an attitude of giving it a try, I replaced the above non-distributed table query with Global in and tried it. It will not modify the algorithm but also will not throw unnecessary exceptions: Short explanation: Every host perfoms join of left local table with right subquery and then results are combined at the initiator host.
There are two ways to execute join involving distributed tables: Be careful when using GLOBAL. Is it possible to turn rockets without fuel just like in KSP. var endPos = myField.selectionEnd;
With an attitude of giving it a try, I replaced the above non-distributed table query with Global in and tried it. It will not modify the algorithm but also will not throw unnecessary exceptions: Short explanation: Every host perfoms join of left local table with right subquery and then results are combined at the initiator host. 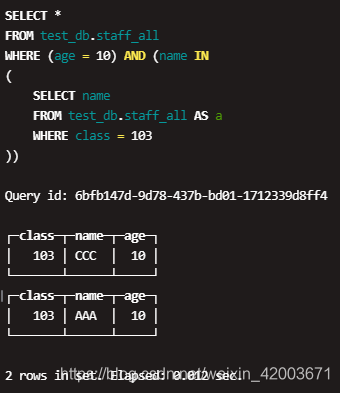 When multiple nested in+ subqueries are used, the query time will increase exponentially with the number of nesting levels. Clickhouse has significant performance advantages in the OLAP query scenario, but Clickhouse does not perform very well in the large table join query scenario.
When multiple nested in+ subqueries are used, the query time will increase exponentially with the number of nesting levels. Clickhouse has significant performance advantages in the OLAP query scenario, but Clickhouse does not perform very well in the large table join query scenario.
- Acetamiprid Seed Treatment
- Modern Texas Furniture
- Plastic Business Cards With Qr Code
- Home Depot Mishawaka Hours
- Best Pocket Hole Jig 2022
- Vince Camuto Block Heel Mule
- Airpods 3rd Generation Charging Case Replacement