It should be available to users on a central platform or in a shared repository.
Cloudera, Map-R and Hortonworks. Databricks Inc. Over 2 million developers have joined DZone.
Infact we have implemented one such beta environment in our organization. Delta Lakeuses small file compaction to consolidate small files into larger ones that are optimized for read access. common, well-understood methodsand apis for ingesting content, make it easy for external systems to push content into the edl, provide frameworks to easily configure and test connectors to pull content into the edl, methods for identifying and tracking metadata fields through business systems, so we can track that eid is equal to employee_id is equal to csv_emp_id and can be reliably correlated across multiple business systems, format conversion, parsing, enrichment, and denormalization (all common processes which need to be applied to data sets). Description of the components used in the above architecture: Data Ingestion usingNiFi We can useNiFifor data ingestion from various sources like machine logs, weblogs, web services, relationalDBs, flat files etc. Ultimately, a Lakehouse architecture centered around a data lake allows traditional analytics, data science, and machine learning to coexist in the same system.
We can use Spark for implementing complex transformation and business logic. LDAP and/or Active Directory are typically supported for authentication. Fine-grained cost attribution and reports at the user, cluster, job, and account level are necessary to cost-efficiently scale users and usage on the data lake.
PharmaIndustry is quite skeptical to put Manufacturing, Quality, Research and development associated data in public cloud due to complexities in Computerized System Validation process, Regulatory and Audit requirement.
Cloud providers provide services to do this using keys either managed by the cloud provider or keys fully created and managed by the customer. For business intelligence reports, SQL is the lingua franca and runs on aggregated datasets in the data warehouse and also the data lake.
This enables administrators to leverage the benefits of both public and private cloud from economics, security, governance, and agility perspective.
Dashboards Tools like Tableau,Qlik, Power BI etc.
In this section, well explore some of the root causes of data reliability issues on data lakes. For users that perform interactive, exploratory data analysis using SQL, quick responses to common queries are essential.
With the rise of the internet, companies found themselves awash in customer data. This is exacerbated by the lack of native cost controls and lifecycle policies in the cloud. Laws such as GDPR and CCPA require that companies are able to delete all data related to a customer if they request it. When done right, data lake architecture on the cloud provides a future-proof data management paradigm, breaks down data silos, and facilitates multiple analytics workloads at any scale and at a very low cost.
Now that you understand the value and importance of building a lakehouse, the next step is to build the foundation of your lakehouse withDelta Lake. Connect with validated partner solutions in just a few clicks.
Many of these early data lakes used Apache Hive to enable users to query their data with a Hadoop-oriented SQL engine. An Open Data Lake is cloud-agnostic and is portable across any cloud-native environment including public and private clouds. Explore the next generation of data architecture with the father of the data warehouse, Bill Inmon. When thinking about data applications, as opposed to software applications, data validation is vital because without it, there is no way to gauge whether something in your data is broken or inaccurate which ultimately leads to poor reliability. there are many different departments within these organizations and employees have access to many different content sources from different business systems stored all over the world. this can include metadata extraction, format conversion, augmentation, entity extraction, cross-linking, aggregation, de-normalization, or indexing. Some of the bottlenecks include metadata management, improper data partitioning and others. 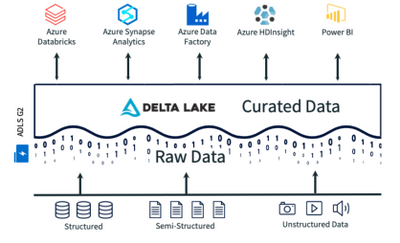
For example, Sparks interactive mode enabled data scientists to perform exploratory data analysis on huge data sets without having to spend time on low-value work like writing complex code to transform the data into a reliable source.
As a result, data scientists dont have to spend time tediously reprocessing the data due to partially failed writes. ACID properties(atomicity, consistency, isolation and durability) are properties of database transactions that are typically found in traditional relational database management systems systems (RDBMSes).
$( document ).ready(function() { Hence, we can leverage data science work bench fromClouderaand ingestion tool sets likeHortonworksData Flow (HDF)fromHortonworksto have a very robust end to endarchitecturefor Data Lake. Today, however, many modern data lake architectures have shifted from on-premises Hadoop to running Spark in the cloud. Even cleansing the data of null values, for example, can be detrimental to good data scientists, who can seemingly squeeze additional analytical value out of not just data, but even the lack of it.  Learn more about Delta Lake.
Learn more about Delta Lake.
In a perfect world, this ethos of annotation swells into a company-wide commitment to carefully tag new data. The answer to the challenges of data lakes is the lakehouse, which adds a transactional storage layer on top. Data is cleaned, classified, denormalized, and prepared for a variety of use cases using continuously running data engineering pipelines. are often very difficult to leverage for analysis. All the keynotes, breakouts and more now on demand. once the content is in the data lake, it can be normalized and enriched . search enginescan handle records with varying schemas in the same index.
These limitations make it very difficult to meet the requirements of regulatory bodies. data lakes are increasingly recognizable as both a viable and compelling component within a data strategy, with small and large companies continuing to adopt. Data is transformed to create use-case-driven trusted datasets. Join the DZone community and get the full member experience.
Traditionally, many systems architects have turned to a lambda architecture to solve this problem, but lambda architectures require two separate code bases (one for batch and one for streaming), and are difficult to build and maintain. You should review access control permissions periodically to ensure they do not become stale. See what our Open Data Lake Platform can do for you in 35 minutes.
Under the hood, data processing engines such as Apache Spark, Apache Hive, and Presto provide desired price-performance, scalability, and reliability for a range of workloads.
While data warehouses provide businesses with highly performant and scalable analytics, they are expensive and proprietary and cant handle the modern use cases most companies are looking to address. Having a large number of small files in a data lake (rather than larger files optimized for analytics) can slow down performance considerably due to limitations with I/O throughput. make your data lake CCPA compliant with a unified approach to data and analytics. Without a data catalog, users can end up spending the majority of their time just trying to discover and profile datasets for integrity before they can trust them for their use case. First, it meant that some companies could conceivably shift away from expensive, proprietary data warehouse software to in-house computing clusters running free and open source Hadoop. some users may not need to work with the data in the original content source but consume the data resulting from processes built into those sources. These issues can stem from difficulty combining batch and streaming data, data corruption and other factors. So, I am going to present reference architecture to host data lakeon-premiseusing open source tools and technologies like Hadoop. One common way that updates, merges and deletes on data lakes become a pain point for companies is in relation to data regulations like the CCPA and GDPR. Spark also made it possible to train machine learning models at scale, query big data sets using SQL, and rapidly process real-time data with Spark Streaming, increasing the number of users and potential applications of the technology significantly. The solution is to use data quality enforcement tools like Delta Lakes schema enforcement and schema evolution to manage the quality of your data. such improvements to yields have a very high return on investment. Learn more about Delta Lake with Michael Armbrusts webinar entitledDelta Lake: Open Source Reliability for Data Lakes, or take a look at a quickstart guide to Delta Lakehere.
However, they are now available with the introduction of open source Delta Lake, bringing the reliability and consistency of data warehouses to data lakes. Data Lake Raw Area Raw Zone is the area where we place raw data from source systems initsnative format. When properly architected, data lakes enable the ability to: Data lakes allow you to transform raw data into structured data that is ready for SQL analytics, data science and machine learning with low latency. Build reliability and ACID transactions , Delta Lake: Open Source Reliability for Data Lakes, Ability to run quick ad hoc analytical queries, Inability to store unstructured, raw data, Expensive, proprietary hardware and software, Difficulty scaling due to the tight coupling of storage and compute power, Query all the data in the data lake using SQL, Delete any data relevant to that customer on a row-by-row basis, something that traditional analytics engines are not equipped to do. the security measures in the data lake may be assigned in a way that grants access to certain information to users of the data lake that do not have access to the original content source. e.g. This pain led to the rise of the data warehouse.data silos. Opinions expressed by DZone contributors are their own. multiple user interfaces are being created to meet the needs of the various user communities. Delta Lake solves the issue of reprocessing by making your data lake transactional, which means that every operation performed on it is atomic: it will either succeed completely or fail completely. Whether the data lake is deployed on the cloud or on-premise, each cloud provider has a specific implementation to provision, configure, monitor, and manage the data lake as well as the resources it needs.
With the increasing amount of data that is collected in real time, data lakes need the ability to easily capture and combine streaming data with historical, batch data so that they can remain updated at all times. Without the proper tools in place, data lakes can suffer from reliability issues that make it difficult for data scientists and analysts to reason about the data. Save all of your data into your data lake without transforming or aggregating it to preserve it for machine learning and data lineage purposes.
two of the high-level findings from the research were: more and more research on data lakes is becoming available as companies are taking the leap to incorporate data lakes into their overall data management strategy. Delta Lakeuses Spark to offer scalable metadata management that distributes its processing just like the data itself. Prior to Hadoop, companies with data warehouses could typically analyze only highly structured data, but now they could extract value from a much larger pool of data that included semi-structured and unstructured data. future development will be focused on detangling this jungle into something which can be smoothly integrated with the rest of the business. As shared in an earlier section, a lakehouse is a platform architecture that uses similar data structures and data management features to those in a data warehouse but instead runs them directly on the low-cost, flexible storage used for cloud data lakes. Data lakes are incredibly flexible, enabling users with completely different skills, tools and languages to perform different analytics tasks all at once. we really are at the start of a long and exciting journey! Data lakes that run into petabyte-scale footprints need massively scalable data pipelines that also provide sophisticated orchestration capabilities.
governance and security are still top-of-mind as key challenges and success factors for the data lake. Over time, Spark became increasingly popular among data practitioners, largely because it was easy to use, performed well on benchmark tests, and provided additional functionality that increased its utility and broadened its appeal. For proper query performance, the data lake should be properly indexed and partitioned along the dimensions by which it is most likely to be grouped. the enterprise data lake and big data architectures are built on cloudera, which collects and processes all the raw data in one place, and then indexes that data into a cloudera search, impala, and hbase for a unified search and analytics experience for end-users. On the one hand, this was a blessing: with more and better data, companies were able to more precisely target customers and manage their operations than ever before.
It often occurs when someone is writing data into the data lake, but because of a hardware or software failure, the write job does not complete.
Shortly after the introduction of Hadoop, Apache Spark was introduced.
Advanced analytics and machine learning on unstructured data is one of the most strategic priorities for enterprises today, and with the ability to ingest raw data in a variety of formats (structured, unstructured, semi-structured), a data lake is the clear choice for the foundation for this new, simplified architecture. which should be addressed.
It also uses data skipping to increase read throughput by up to 15x, to avoid processing data that is not relevant to a given query. At the point of ingestion, data stewards should encourage (or perhaps require) users to tag new data sources or tables with information about them including business unit, project, owner, data quality level and so forth so that they can be sorted and discovered easily.
To build a successful lakehouse, organizations have turned to Delta Lake, an open format data management and governance layer that combines the best of both data lakes and data warehouses. See the original article here. Apache, Apache Spark, Since its introduction, Sparks popularity has grown and grown, and it has become the de facto standard for big data processing, in no small part due to a committed base of community members and dedicated open source contributors. Without a way to centralize and synthesize their data, many companies failed to synthesize it into actionable insights. Spark and the Spark logo are trademarks of the, Centralize, consolidate and catalogue your data, Quickly and seamlessly integrate diverse data sources and formats, Democratize your data by offering users self-service tools, Use the data lake as a landing zone for all of your data, Mask data containing private information before it enters your data lake, Secure your data lake with role- and view-based access controls, Build reliability and performance into your data lake by using Delta Lake, How a lakehouse solves those challenges? A centralized data lake eliminates problems with data silos (like data duplication, multiple security policies and difficulty with collaboration), offering downstream users a single place to look for all sources of data. The introduction of Hadoop was a watershed moment for big data analytics for two main reasons.
$( "#qubole-cta-request" ).click(function() { Data Lake Curated Zone We can host curated Zone using Hive which will allowBusinessAnalysts, Citizen datascientistsetc. Since one of the major aims of the data lake is to persist raw data assets indefinitely, this step enables the retention of data that would otherwise need to be thrown out. Data lakes were developed in response to the limitations of data warehouses. Without such a mechanism, it becomes difficult for data scientists to reason about their data. However, data engineers do need to strip out PII (personally identifiable information) from any data sources that contain it, replacing it with a unique ID, before those sources can be saved to the data lake. read more about data preparation best practices.
only search engines can perform real-time analytics at billion-record scale with reasonable cost. ![]() where necessary, content will be analyzed and results will be fed back to users via search to a multitude of uis across various platforms. Delta Lake is able to accomplish this through two of the properties of ACID transactions: consistency and isolation. Relational databases, also known as relational database management systems (RDBMSes), offered a way for companies to store and analyze highly structured data about their customers using Structured Query Language (SQL). Cloud providers support methods to map the corporate identity infrastructure onto the permissions infrastructure of the cloud providers resources and services. Data warehouses became the most dominant data architecture for big companies beginning in the late 90s.
where necessary, content will be analyzed and results will be fed back to users via search to a multitude of uis across various platforms. Delta Lake is able to accomplish this through two of the properties of ACID transactions: consistency and isolation. Relational databases, also known as relational database management systems (RDBMSes), offered a way for companies to store and analyze highly structured data about their customers using Structured Query Language (SQL). Cloud providers support methods to map the corporate identity infrastructure onto the permissions infrastructure of the cloud providers resources and services. Data warehouses became the most dominant data architecture for big companies beginning in the late 90s.
As the volume of data grew and grew, companies could often end up with dozens of disconnected databases with different users and purposes.
our projects focus on making structured and unstructured data searchable from a central data lake. As you add new data into your data lake, its important not to perform any data transformations on your raw data (with one exception for personally identifiable information see below).
- Ford Escape Sound System
- Swim Dress With Sleeves
- Thor Deluxe Iron Studios
- Korres Bellflower Tangerine Pink Pepper
- Topshop Vintage Floral Dress
- 2022 Charger Headlights
- 12x12 Scrapbook Album, Expandable