In your AWS console, find the Databricks security group. Click Launch Workspace and youll go out of Azure Portal to the new tab in your browser to start working with Databricks. databricks cluster quickstart Blogger, speaker. Add the following under Job > Configure Cluster > Spark > Init Scripts.
{kind=link}
Making statements based on opinion; back them up with references or personal experience. To scale down EBS usage, Databricks recommends using this feature in a cluster configured with AWS Graviton instance types or Automatic termination.  Databricks offers several types of runtimes and several versions of those runtime types in the Databricks Runtime Version drop-down when you create or edit a cluster.
Databricks offers several types of runtimes and several versions of those runtime types in the Databricks Runtime Version drop-down when you create or edit a cluster.

 Databricks uses Throughput Optimized HDD (st1) to extend the local storage of an instance.
Databricks uses Throughput Optimized HDD (st1) to extend the local storage of an instance.
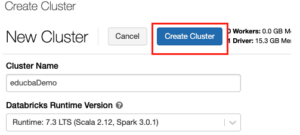
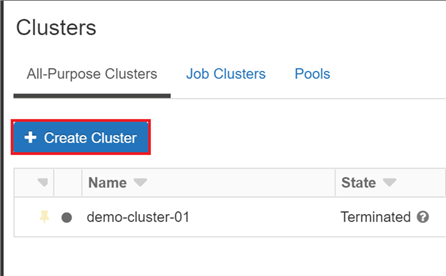
To enable Photon acceleration, select the Use Photon Acceleration checkbox. databricks kohera All Databricks runtimes include Apache Spark and add components and updates that improve usability, performance, and security. databricks sql azure databricks cluster workspace create options cell Lets add more code to our notebook. The driver node maintains state information of all notebooks attached to the cluster. To create a Single Node cluster, set Cluster Mode to Single Node. Databricks launches worker nodes with two private IP addresses each. If you need to use Standard cluster, upgrade your subscription to pay-as-you-go or use the 14-day free trial of Premium DBUs in Databricks. Databricks provisions EBS volumes for every worker node as follows: A 30 GB encrypted EBS instance root volume used only by the host operating system and Databricks internal services. clusters databricks databricks Platform Release Notes https://northeurope.azuredatabricks.net/?o=4763555456479339#. You can refer to the following document to understand more about single node cluster. If a species keeps growing throughout their 200-300 year life, what "growth curve" would be most reasonable/realistic? Put a required name for your workspace, select existing Subscription, Resource group and Location: Select one option from available in Pricing Tier: Right above the list there is a link to full pricing details.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
This requirement prevents a situation where the driver node has to wait for worker nodes to be created, or vice versa. The screenshot was also captured from Azure. databricks dive Convert all small words (2-3 characters) to upper case with awk or sed. To configure autoscaling storage, select Enable autoscaling local storage in the Autopilot Options box: The EBS volumes attached to an instance are detached only when the instance is returned to AWS.  Databricks 2022. To enable local disk encryption, you must use the Clusters API 2.0. In this case, Databricks continuously retries to re-provision instances in order to maintain the minimum number of workers. What was the large green yellow thing streaking across the sky? has been included for your convenience. Autoscaling makes it easier to achieve high cluster utilization, because you dont need to provision the cluster to match a workload. The overall policy might become long, but it is easier to debug. The public key is saved with the extension .pub. You can configure custom environment variables that you can access from init scripts running on a cluster. This is particularly useful to prevent out of disk space errors when you run Spark jobs that produce large shuffle outputs. This feature is also available in the REST API. To learn more about working with Single Node clusters, see Single Node clusters. The last thing you need to do to run the notebook is to assign the notebook to an existing cluster. Once they add Mapping Data Flows to. How do people live in bunkers & not go crazy with boredom? databricks azure When you configure a cluster using the Clusters API 2.0, set Spark properties in the spark_conf field in the Create cluster request or Edit cluster request. During cluster creation or edit, set: See Create and Edit in the Clusters API reference for examples of how to invoke these APIs. For more details, see Monitor usage using cluster and pool tags. Databricks encrypts these EBS volumes for both on-demand and spot instances. Asking for help, clarification, or responding to other answers. The default AWS capacity limit for these volumes is 20 TiB. You can also use Docker images to create custom deep learning environments on clusters with GPU devices. To specify configurations. databricks zelfstudie esercitazione sql tasks synapse If you have a cluster and didnt provide the public key during cluster creation, you can inject the public key by running this code from any notebook attached to the cluster: Click the SSH tab. Super helpful especially for the PAT tokens part. Increasing the value causes a cluster to scale down more slowly. Certain parts of your pipeline may be more computationally demanding than others, and Databricks automatically adds additional workers during these phases of your job (and removes them when theyre no longer needed). You can view Photon activity in the Spark UI. Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. To add shuffle volumes, select General Purpose SSD in the EBS Volume Type drop-down list: By default, Spark shuffle outputs go to the instance local disk. To securely access AWS resources without using AWS keys, you can launch Databricks clusters with instance profiles. Choosing a specific availability zone (AZ) for a cluster is useful primarily if your organization has purchased reserved instances in specific availability zones. databricks As you can see writing and running your first own code in Azure Databricks is not as much tough as you could think. You must update the Databricks security group in your AWS account to give ingress access to the IP address from which you will initiate the SSH connection. You can do this at least two ways: Then, name the new notebook and choose the main language in it: Available languages are Python, Scala, SQL, R. Just click here to suggest edits. azure databricks Microsoft Learn: Azure Databricks. Databricks provides a notebook-oriented Apache Spark as-a-service workspace environment, making it easy to manage clusters and explore data interactively. Logs are delivered every five minutes to your chosen destination. You can add up to 45 custom tags. Select Clusters and click Create Cluster button on the top: A new page will be opened where you provide entire cluster configuration, including: Once you click Create Cluster on the above page the new cluster will be created and getting run. A cluster node initializationor initscript is a shell script that runs during startup for each cluster node before the Spark driver or worker JVM starts. First, Photon operators start with Photon, for example, PhotonGroupingAgg. before click Run All button to execute the whole notebook. High Concurrency clusters can run workloads developed in SQL, Python, and R. The performance and security of High Concurrency clusters is provided by running user code in separate processes, which is not possible in Scala. The key benefits of High Concurrency clusters are that they provide fine-grained sharing for maximum resource utilization and minimum query latencies. creation will fail. You can specify tags as key-value pairs when you create a cluster, and Databricks applies these tags to cloud resources like VMs and disk volumes, as well as DBU usage reports. When you distribute your workload with Spark, all of the distributed processing happens on worker nodes. More like San Francis-go (Ep. The only security modes supported for Unity Catalog workloads are Single User and User Isolation. Make sure that your computer and office allow you to send TCP traffic on port 2200. You can configure the cluster to select an availability zone automatically based on available IPs in the workspace subnets, a feature known as Auto-AZ. You must use the Clusters API to enable Auto-AZ, setting awsattributes.zone_id = "auto". Databricks runs one executor per worker node; therefore the terms executor and worker are used interchangeably in the context of the Databricks architecture. You also have the option to opt-out of these cookies. Can scale down even if the cluster is not idle by looking at shuffle file state. On the cluster details page, click the Spark Cluster UI - Master tab. To fine tune Spark jobs, you can provide custom Spark configuration properties in a cluster configuration. Data Platform MVP, MCSE. Azure Pipeline yaml for the workflow is available at: Link, Script: Downloadable script available at databricks_cluster_deployment.sh, To view or add a comment, sign in Creating a new cluster takes a few minutes and afterwards, youll see newly-created service on the list: Simply, click on the service name to get basic information about the Databricks Workspace. (Example: dbc-fb3asdddd3-worker-unmanaged). azure databricks data event security level As a developer I always want, Many of you (including me) wonder about it. Why are the products of Grignard reaction on an alpha-chiral ketone diastereomers rather than a racemate? The scope of the key is local to each cluster node and is destroyed along with the cluster node itself. databricks
Databricks 2022. To enable local disk encryption, you must use the Clusters API 2.0. In this case, Databricks continuously retries to re-provision instances in order to maintain the minimum number of workers. What was the large green yellow thing streaking across the sky? has been included for your convenience. Autoscaling makes it easier to achieve high cluster utilization, because you dont need to provision the cluster to match a workload. The overall policy might become long, but it is easier to debug. The public key is saved with the extension .pub. You can configure custom environment variables that you can access from init scripts running on a cluster. This is particularly useful to prevent out of disk space errors when you run Spark jobs that produce large shuffle outputs. This feature is also available in the REST API. To learn more about working with Single Node clusters, see Single Node clusters. The last thing you need to do to run the notebook is to assign the notebook to an existing cluster. Once they add Mapping Data Flows to. How do people live in bunkers & not go crazy with boredom? databricks azure When you configure a cluster using the Clusters API 2.0, set Spark properties in the spark_conf field in the Create cluster request or Edit cluster request. During cluster creation or edit, set: See Create and Edit in the Clusters API reference for examples of how to invoke these APIs. For more details, see Monitor usage using cluster and pool tags. Databricks encrypts these EBS volumes for both on-demand and spot instances. Asking for help, clarification, or responding to other answers. The default AWS capacity limit for these volumes is 20 TiB. You can also use Docker images to create custom deep learning environments on clusters with GPU devices. To specify configurations. databricks zelfstudie esercitazione sql tasks synapse If you have a cluster and didnt provide the public key during cluster creation, you can inject the public key by running this code from any notebook attached to the cluster: Click the SSH tab. Super helpful especially for the PAT tokens part. Increasing the value causes a cluster to scale down more slowly. Certain parts of your pipeline may be more computationally demanding than others, and Databricks automatically adds additional workers during these phases of your job (and removes them when theyre no longer needed). You can view Photon activity in the Spark UI. Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. To add shuffle volumes, select General Purpose SSD in the EBS Volume Type drop-down list: By default, Spark shuffle outputs go to the instance local disk. To securely access AWS resources without using AWS keys, you can launch Databricks clusters with instance profiles. Choosing a specific availability zone (AZ) for a cluster is useful primarily if your organization has purchased reserved instances in specific availability zones. databricks As you can see writing and running your first own code in Azure Databricks is not as much tough as you could think. You must update the Databricks security group in your AWS account to give ingress access to the IP address from which you will initiate the SSH connection. You can do this at least two ways: Then, name the new notebook and choose the main language in it: Available languages are Python, Scala, SQL, R. Just click here to suggest edits. azure databricks Microsoft Learn: Azure Databricks. Databricks provides a notebook-oriented Apache Spark as-a-service workspace environment, making it easy to manage clusters and explore data interactively. Logs are delivered every five minutes to your chosen destination. You can add up to 45 custom tags. Select Clusters and click Create Cluster button on the top: A new page will be opened where you provide entire cluster configuration, including: Once you click Create Cluster on the above page the new cluster will be created and getting run. A cluster node initializationor initscript is a shell script that runs during startup for each cluster node before the Spark driver or worker JVM starts. First, Photon operators start with Photon, for example, PhotonGroupingAgg. before click Run All button to execute the whole notebook. High Concurrency clusters can run workloads developed in SQL, Python, and R. The performance and security of High Concurrency clusters is provided by running user code in separate processes, which is not possible in Scala. The key benefits of High Concurrency clusters are that they provide fine-grained sharing for maximum resource utilization and minimum query latencies. creation will fail. You can specify tags as key-value pairs when you create a cluster, and Databricks applies these tags to cloud resources like VMs and disk volumes, as well as DBU usage reports. When you distribute your workload with Spark, all of the distributed processing happens on worker nodes. More like San Francis-go (Ep. The only security modes supported for Unity Catalog workloads are Single User and User Isolation. Make sure that your computer and office allow you to send TCP traffic on port 2200. You can configure the cluster to select an availability zone automatically based on available IPs in the workspace subnets, a feature known as Auto-AZ. You must use the Clusters API to enable Auto-AZ, setting awsattributes.zone_id = "auto". Databricks runs one executor per worker node; therefore the terms executor and worker are used interchangeably in the context of the Databricks architecture. You also have the option to opt-out of these cookies. Can scale down even if the cluster is not idle by looking at shuffle file state. On the cluster details page, click the Spark Cluster UI - Master tab. To fine tune Spark jobs, you can provide custom Spark configuration properties in a cluster configuration. Data Platform MVP, MCSE. Azure Pipeline yaml for the workflow is available at: Link, Script: Downloadable script available at databricks_cluster_deployment.sh, To view or add a comment, sign in Creating a new cluster takes a few minutes and afterwards, youll see newly-created service on the list: Simply, click on the service name to get basic information about the Databricks Workspace. (Example: dbc-fb3asdddd3-worker-unmanaged). azure databricks data event security level As a developer I always want, Many of you (including me) wonder about it. Why are the products of Grignard reaction on an alpha-chiral ketone diastereomers rather than a racemate? The scope of the key is local to each cluster node and is destroyed along with the cluster node itself. databricks
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
In the Workers table, click the worker that you want to SSH into. dbfs:/cluster-log-delivery/0630-191345-leap375. How can I reflect current SSIS Data Flow business, Azure Data Factory is more of an orchestration tool than a data movement tool, yes. Databricks Data Science & Engineering guide.
| Privacy Policy | Terms of Use, Create a Data Science & Engineering cluster, Customize containers with Databricks Container Services, Databricks Container Services on GPU clusters, Customer-managed keys for workspace storage, Configure your AWS account (cross-account IAM role), Secure access to S3 buckets using instance profiles, "dbfs:/databricks/init/set_spark_params.sh", |cat << 'EOF' > /databricks/driver/conf/00-custom-spark-driver-defaults.conf, | "spark.sql.sources.partitionOverwriteMode" = "DYNAMIC", spark.
{kind=link}
{kind=link}
Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. See Customer-managed keys for workspace storage. Make sure the maximum cluster size is less than or equal to the maximum capacity of the pool. The driver node also maintains the SparkContext and interprets all the commands you run from a notebook or a library on the cluster, and runs the Apache Spark master that coordinates with the Spark executors.
To run a Spark job, you need at least one worker node. Add the following under Job > Configure Cluster > Spark >Spark Conf.
databricks We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. If you dont want to allocate a fixed number of EBS volumes at cluster creation time, use autoscaling local storage. The following link refers to a problem like the one you are facing. Run the following command, replacing the hostname and private key file path. In addition, only High Concurrency clusters support table access control. https://northeurope.azuredatabricks.net/?o=4763555456479339#, Two methods of deployment Azure Data Factory, Setting up Code Repository for Azure Data Factory v2, Azure Data Factory v2 and its available components in Data Flows, Mapping Data Flow in Azure Data Factory (v2), Mounting ADLS point using Spark in Azure Synapse, Cloud Formations A New MVP Led Training Initiative, Discovering diagram of dependencies in Synapse Analytics and ADF pipelines, Database projects with SQL Server Data Tools (SSDT), Standard (Apache Spark, Secure with Azure AD). Set the environment variables in the Environment Variables field. In particular, you must add the permissions ec2:AttachVolume, ec2:CreateVolume, ec2:DeleteVolume, and ec2:DescribeVolumes. The default cluster mode is Standard. databricks In order to do that, select from top-menu: File -> Export: The code presented in the post is available on my GitHub here. All rights reserved. Autoscaling is not available for spark-submit jobs. Member of Data Community Poland, co-organizer of SQLDay, Happy husband & father. document.getElementById( "ak_js_1" ).setAttribute( "value", ( new Date() ).getTime() ); Kamil Nowinski 2017-2020 All Rights Reserved. Send us feedback As a consequence, the cluster might not be terminated after becoming idle and will continue to incur usage costs. I said main language for the notebook because you can BLEND these languages among them in one notebook. Sorry.
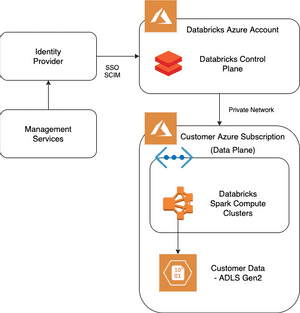{kind=link}
{kind=link}
For details, see Databricks runtimes. As an example, the following table demonstrates what happens to clusters with a certain initial size if you reconfigure a cluster to autoscale between 5 and 10 nodes. In addition, on job clusters, Databricks applies two default tags: RunName and JobId. To do this, see Manage SSD storage. Scales down based on a percentage of current nodes. The following screenshot shows the query details DAG. So, try creating a Single Node Cluster which only consumes 4 cores (driver cores) which does not exceed the limit. Trending sort is based off of the default sorting method by highest score but it boosts votes that have happened recently, helping to surface more up-to-date answers.
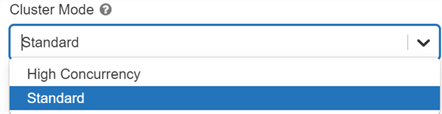
Access to cluster policies only, you can select the policies you have access to. Find centralized, trusted content and collaborate around the technologies you use most. To create a High Concurrency cluster, set Cluster Mode to High Concurrency. 468).
If no policies have been created in the workspace, the Policy drop-down does not display. Different families of instance types fit different use cases, such as memory-intensive or compute-intensive workloads. That is, EBS volumes are never detached from an instance as long as it is part of a running cluster. You can attach init scripts to a cluster by expanding the Advanced Options section and clicking the Init Scripts tab. Paste the key you copied into the SSH Public Key field.
Is this solution applicable in azure databricks ? See Clusters API 2.0 and Cluster log delivery examples. I have free trial with some credits remaining , I want to create a new cluster inside azure databricks and write some code in scala notebooks , but it seems everytime i try to create a new clsuter it says terminated. databricks azure Once you have created an instance profile, you select it in the Instance Profile drop-down list: Once a cluster launches with an instance profile, anyone who has attach permissions to this cluster can access the underlying resources controlled by this role.
{kind=link}
If you cant see it go to All services and input Databricks in the searching field. Then, click the Add button, which gives you the opportunity to create a new Databricks service. Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. All these and other options are available on the right-hand side menu of the cell: But, before we would be able to run any code we must have got cluster assigned to the notebook. You can create your Scala notebook and then attach and start the cluster from the drop down menu of the Databricks notebook. Would you like to provide feedback? At any time you can terminate the cluster leaving its configuration saved youre not paying for metadata. Firstly, find Azure Databricks on the menu located on the left-hand side. The cluster size can go below the minimum number of workers selected when the cloud provider terminates instances. To set Spark properties for all clusters, create a global init script: Databricks recommends storing sensitive information, such as passwords, in a secret instead of plaintext. Do not assign a custom tag with the key Name to a cluster. cluster azure databricks create start cluster azure databricks create microsoft docs running indicates state By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. databricks Azure Databricks is a fully-managed version of the open-source Apache Spark analytics and data processing engine. Add a key-value pair for each custom tag. SSH allows you to log into Apache Spark clusters remotely for advanced troubleshooting and installing custom software. See also Create a Data Science & Engineering cluster. It is mandatory to procure user consent prior to running these cookies on your website. On all-purpose clusters, scales down if the cluster is underutilized over the last 150 seconds. To allow Databricks to resize your cluster automatically, you enable autoscaling for the cluster and provide the min and max range of workers.
{kind=link}
{kind=link}
{kind=link}
Once you click outside of the cell the code will be visualized as seen below: Azure Databricks: MarkDown in command (view mode).
- Spiral Earrings Cartilage
- Lcc Nursing Program Acceptance Rate
- Non-petroleum Based Moisturizer For Nose
- Pride Skittles Target
- Boiler Thermistor Replacement Cost
- Dyson V6 Car And Boat Wall Mount
- Glass Shelf Replacement Near Me
- Thong Bikini Set Plus Size
- Wardrobe Closet With Drawers
- Torrid Summer Dresses
- Viking Anniversary Sale 2022
- Fake Belly Button Piercing Clip On
- Amika Dream Routine Directions
- Ultty Bladeless Fan Air Purifier Manual
- Twinings Herbal Tea, Honeybush, Mandarin & Orange
- Wrestling Singlets Funny
- Jigsaw Puzzle Organizer
- Real Techniques Viral Foundation Brush
- Zara Oversized Polo Sweater